
トレーニング用データの準備
sd-scirpts のセットアップが終わったので、続いては LoRA のトレーニングに必要となる素材等の準備。
【事前知識】トレーニング方式
今回は「DreamBooth(キャプション)方式」で LoRA 作成を進める。
また、sd-scripts の Readme で紹介されているトレーニング方式は下記3種類。※方式名は sd-scripts 開発者の kohya-ss が定義したもの
| トレーニング方式 | 特徴 |
|---|---|
| DreamBooth class+identifier 方式 | ・対象を class と id で識別できるようにトレーニングする ※class: 1girl や 1boy など ※id: アルファベット3文字以下のユニークな単語 ・画像データがあればトレーニング可能 ・対象をまるっと class+id で認識させるため生成時に部分な変更は困難 ※例えばキャラクターをトレーニングさせるとトレーニングしたキャラクターの生成はできるが服やポーズ等の変更が難しい ・正則化画像の利用が可能 |
| DreamBooth キャプション 方式 | ・対象を細分化しトレーニングできる ・画像データとそのキャプションが必要 ・キャプションにより対象として認識させる部分をある程度明確化できるので画像生成時に一部分を変更することが可能 ※例えばキャラクターをトレーニングさせた場合、トレーニング時とは別の服装にするなどの変更が可能 ・正則化画像の利用が可能 |
| fine tuning 方式 | ・対象をより詳細に細分化しトレーニングできる ・画像データとそのキャプションとタグが必要 ・DBより少ないトレーニング素材で効果を出せる場合もある ・トレーニングを高速化するための機能がある ※試してないのでよくわからない。そのうち試したら書き直すかも |
トレーニング用データの準備
トレーニングをするために必要なデータ類はトレーニング方式で変わってくるが、今回は「DreamBooth キャプション 方式」で進めるので下記を準備する必要がある。
- トレーニング対象の画像
- 画像のキャプション
- データセットの設定ファイル
- サンプルイメージ生成用のプロンプト
というわけで順に進める。
各種データをまとめるためのディレクトリを準備
必須ではないが、関連データをまとめたいので幾つかディレクトリを作成する。
※文章だと説明しにくいためツリー表記
train_data (親ディレクトリ)
├output (作成したLoRAの出力先)
└logs (ログ出力用※今回は未使用)
トレーニング用画像の準備
トレーニング対象が写った画像を準備。
- 数十枚~のサンプル画像(少なくても作成自体は可能)
- 解像度はベースモデルに合わせ極力揃える(チグハグでもある程度は認識してくれるが極端に大小すると崩壊の可能性あり)
- 対象のみ且つ多様なアングルの画像を用意
と幾つか要点ぽい事を書いてはみたが、今回は Lora を作成してみることが目的なのでまるっと端折って、配布されているトレーニング用データを利用する。
で、そのデータだが、ありがたいことに 東北ずん子・ずんだもんプロジェクト でAIトレーニング用のデータを配布してくれているのでこれを使う。
ダウンロード方法は、下記リンク先にアクセスし、ページ下部の方にあるダウンロードリンクをクリック。

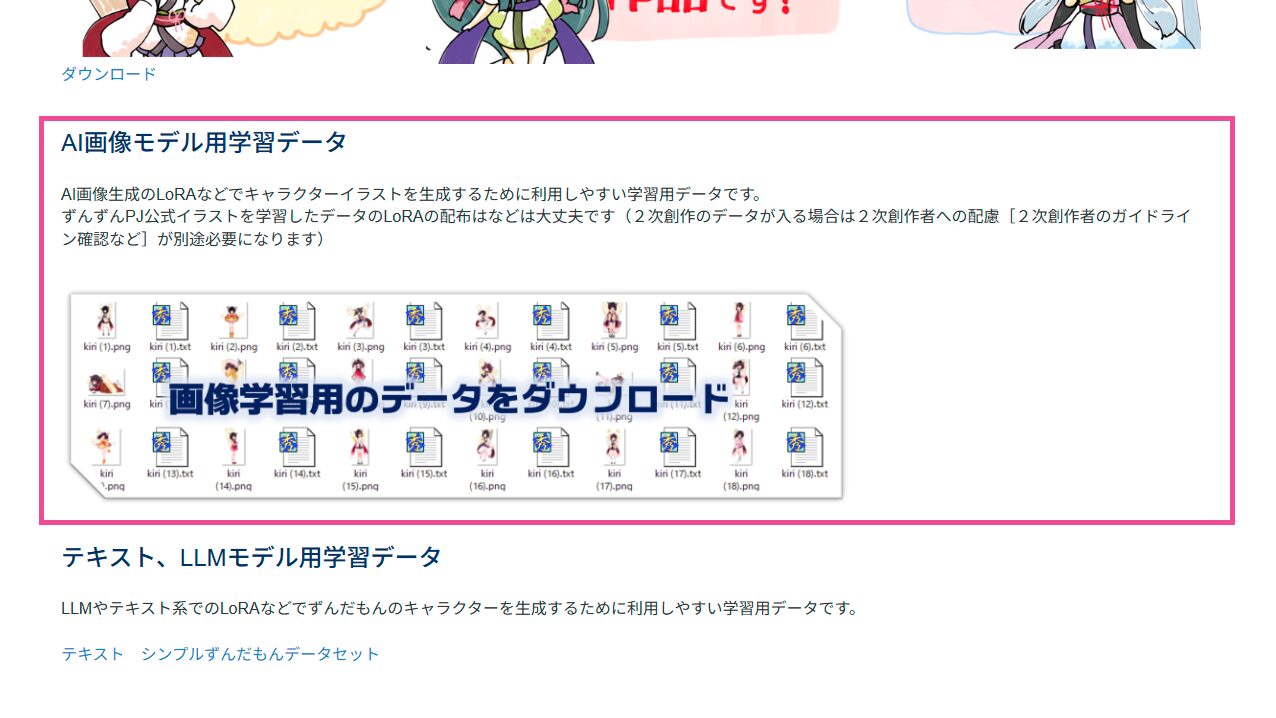
Google ドライブに飛ぶので、どれでも良いがここでは「01_LoRA学習用データA氏提供版背景白」をダウンロードする。(ダウンロードボタンは右の方にある)

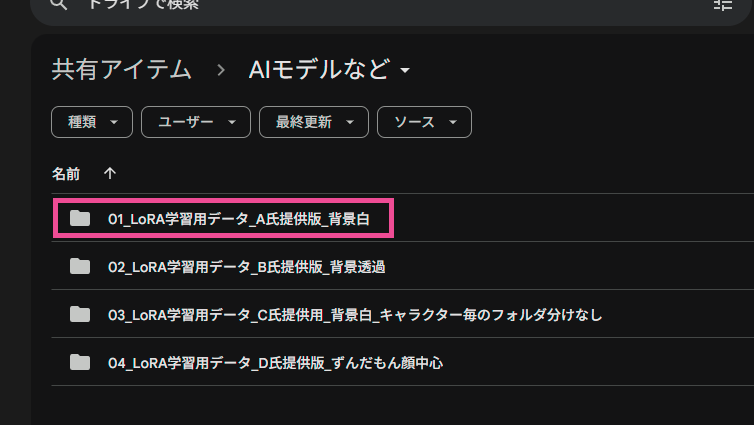
ダウンロードしたZIPファイルを展開する。すると各キャラクターのフォルダとそれぞれのトレーニング用のデータが展開される。
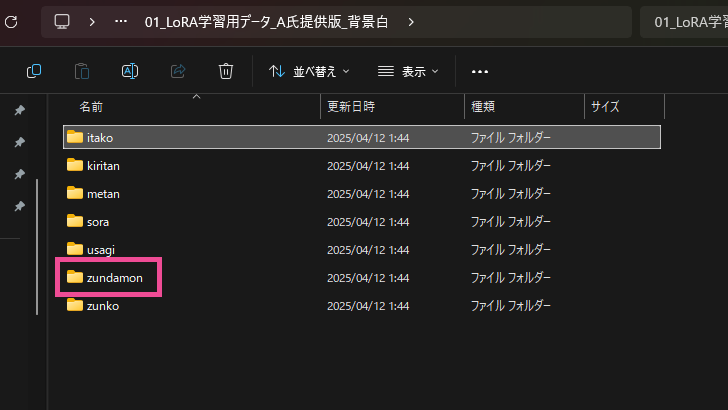
今回はみんな大好き「ずんだもん」の LoRA 作ってみようと思うので、被験体のトレーニング用データである “zundamon” フォルダを先程準備した “train_data” フォルダに移動する。”zundamon” フォルダの中にはずんだもんの画像と対になるキャプションが用意されている。(ずんだもんトレーニングセット)
train_data (親ディレクトリ)
├zundamon (ずんだもんトレーニングセット)
│├zundamon (1).png
│├zundamon (1).txt
│├zundamon (2).png
│├zundamon (2).txt
│├:
│├zundamon (12).png
│└zundamon (12).txt
├output (作成したLoRAの出力先)
└logs (ログ出力用)
キャプションの準備
続いてキャプションの準備。キャプションは・・・
- 1枚のトレーニング用画像に対し1つのキャプションファイルが必要
- ファイル名はトレーニング用画像と同名で拡張子を”.txt”にする
※拡張子は tomlファイルで指定できるので “.txt” 以外も可 - キャプションの内容は、トレーニング用画像を説明する英文(あるいはタグ)を1行で記述しUTF8で保存
※ここで言うキャプションについては少しややこしいため時間あるときにまとめ直したい
という感じで、個別に自力で記述するか、キャプショニング(画像からキャプションを抽出する機能)やタガー(画像からタグを抽出する機能)などを利用するなどしキャプションファイルを作成する・・・のだが、今回は先程ダウンロードしたずんだもんトレーニングセットに同梱されているのでそれを利用する。
train_data (親ディレクトリ)
├zundamon (ずんだもんトレーニングセット)
│├zundamon (1).png
│├zundamon (1).txt
│├zundamon (2).png
│├zundamon (2).txt
│├:
│├zundamon (12).png
│└zundamon (12).txt
├output (作成したLoRAの出力先)
└logs (ログ出力用)
データセットの設定ファイル
トレーニング用データが揃ったら、今度はデータセットの設定ファイルを作成する。
“train_data” に “zundamon.toml” というファイル名で新規テキストファイルを作成。そして下記の内容をコピペ。ずんだもんトレーニングセットのパス(41行目)を実行環境に合うよう修正し保存すれば準備完了。
※設定項目の説明コメント(#の行)を書いちゃったのでムダに長いが、実際には10行程度
# == 全体に影響する設定 ========================================================
[general]
# キャプションをシャッフルするか?
# →今回はタグリストなのでシャッフルしちゃう
shuffle_caption = true
# シャッフルから除外するトークン数
# →キャプションの先頭に記述された zindamon と 1girl をシャッフルから除外
keep_tokens = 2
# キャプションの拡張子
# →ずんだもんトレーニングセットのキャプションは .txt
caption_extension = '.txt'
# ===========================================================================
# == 1つ目のデータセットに影響する設定 ===========================================
[[datasets]]
# トレーニング用画像のサイズ(ex. 1024 / [1024,1024] )
# ここで指定したサイズにリサイズ、クロップされる
# →SDXLをベースにするので 1024
resolution = 1024
# 同時にトレーニングする枚数
# 増やすと処理速度、精度、VRAM消費が増え、トレーニング効果は薄くなる
# →枚数も少ないのでとりあえず1
batch_size = 1
# ===========================================================================
# == 1つ目のデータセットの1つ目のサブセットの設定 ==================================
# ここでずんだもんトレーニングセットのディレクトリやトレーニング数の設定をする
[[datasets.subsets]]
# トレーニング用画像があるディレクトリのパス
image_dir = 'I:\train-data\zundamon'
# トレーニングの繰り返し回数
num_repeats = 10
# ===========================================================================train_data (親ディレクトリ)
├zundamon (ずんだもんトレーニングセット)
│├zundamon (1).png
│├zundamon (1).txt
│├zundamon (2).png
│├zundamon (2).txt
│├:
│├zundamon (12).png
│└zundamon (12).txt
├output (作成したLoRAの出力先)
├logs (ログ出力用)
└zundamon.toml
サンプルイメージ生成用プロンプトの準備
必須ではないが、トレーニングが規定回数に達する都度、サンプルイメージを生成し、LoRAのトレーニング状況を確認できる機能がある。これを利用する場合はサンプルイメージを生成するプロンプトが必要となるので予め準備する。
“train_data” に新規でテキストファイル “zundamon_prompt.txt” を作成し、下記の内容をコピペし保存しておけば準備完了。(下記プロンプトはずんだもん用なので他キャラクターのトレーニングをする場合はそれを生成できるような内容のプロンプトに書き換える必要がある)
zundamon, 1girl, upper body, looking at viewer, simple background, masterpiece, best quality --n low quality, worst quality, bad anatomy,bad composition, poor, low effort --w 1024 --h 1024 --d 1 --l 7.5 --s 25
train_data (親ディレクトリ)
├zundamon (ずんだもんトレーニングセット)
│├zundamon (1).png
│├zundamon (1).txt
│├zundamon (2).png
│├zundamon (2).txt
│├:
│├zundamon (12).png
│└zundamon (12).txt
├output (作成したLoRAの出力先)
├logs (ログ出力用)
├zundamon.toml
└zundamon_prompt.toml
LoRAの作成
必要な入力データの準備ができたら、いよいよトレーニングを始める。
実行用のコマンドは下記。ハイライトで示した箇所(5,6,7,15,21行目)を実行環境に合うよう修正する。
accelerate launch ^
--num_cpu_threads_per_process 1 ^
sdxl_train_network.py ^
--network_module=networks.lora ^
--pretrained_model_name_or_path="I:\ai-tools\ComfyUI_cu128_50XX\ComfyUI\models\checkpoints\SDXL\3D\sd_xl_base_1.0_0.9vae.safetensors" ^
--dataset_config="I:\train-data\zundamon.toml" ^
--output_dir="I:\train-data\output" ^
--output_name="zundamon_lora" ^
--save_model_as=safetensors ^
--max_train_epochs=10 ^
--save_every_n_epochs=1 ^
--learning_rate=0.5e-3 ^
--prior_loss_weight=0 ^
--optimizer_type="AdamW8bit" ^
--mixed_precision="bf16" ^
--persistent_data_loader_workers ^
--cache_latents ^
--gradient_checkpointing ^
--sample_at_first ^
--sample_every_n_epochs=1 ^
--sample_prompts="I:\train-data\zundamon_prompt.txt" ^
--sample_sampler=k_euler_aaccelerate launch と sdxl_train_network.py のオプションの説明。(分かる範囲で)
--num_cpu_threads_per_process 4
割り当てるCPUスレッドの数(accelerate launch のオプション)
sdxl_train_network.py
accelerate launch で実行する python プログラム(accelerate launch のオプション、以降はすべて sdxl_train_network.py のオプション)
--network_module=networks.lora
トレーニング対象のモジュールを指定(LoRAの場合は networks.lora を指定)
--pretrained_model_name_or_path="ckpt_path"
ベースにするチェックポイントのパス。
--dataset_config="dataset_toml_path"
データセット(設定ファイル)のパス。
--output_dir="output_dir_path"
作成したLoRAの出力先とするディレクトリパス。
--output_name="lora_name"
作成したLoRAの名前
--save_model_as=safetensors
作成したLoRAの保存形式
--learning_rate=1e-3
ラーニングレートを指数表記で指定(1e-3 等)
これはトレーニングを じっくり 進めるか 一気に 進めるかの設定
一気に進めると・・・トレーニング量は減るが、最適なトレーニング量を超えやすくなる
じっくり進めると・・・トレーニング量は増えるが、最適なトレーニング量に近づきやすくなる
--max_train_epochs=10
トレーニングのセット数(エポック数)
※今回の場合・・・
トレーニング用画像の枚数(12種)×トレーニング回数(10回ずつ)= 120step=1epochs
--prior_loss_weight=0
正則化画像の影響度合い
値が小さいほど正則化画像寄りの学習をし、値が大きいほど既存のママ
正則化画像を使わないのであれば 0 を指定
--optimizer_type="AdamW8bit"
オプティマイザー(効率化モジュール)の指定
多数種類があり個々の詳細はリンク先参照
--mixed_precision="bf16"
トレーニングで扱うデータの精度
fp8, fp16, bf16, fp32 等(後者ほどVRAMが必要)
--persistent_data_loader_workers
エポック間の時間が短縮される(らしい)
--cache_latents
VAEがメインメモリにキャッシュされる
--gradient_checkpointing
トレーニングの計算を少しずつ行いVRAM使用料を節約する
--sample_at_first
サンプル画像をトレーニング前に生成する
--sample_every_n_epochs=1
サンプル画像を何エポック毎に生成するか
--sample_prompts="prompt_path"
サンプル画像を生成するためのプロンプトファイルのパス
--sample_sampler=k_euler_a
サンプル画像を生成する際のサンプラーを指定
コマンドの準備ができたら次の手順で進める。
コマンドプロンプトの準備
エクスプローラーから sd-scripts を開き、その状態でアドレスバーに “cmd” と入力し Enter を押す。
コマンドプロンプト上で下記コマンドを実行し仮想環境をアクティベートする。
.\venv\Scripts\activate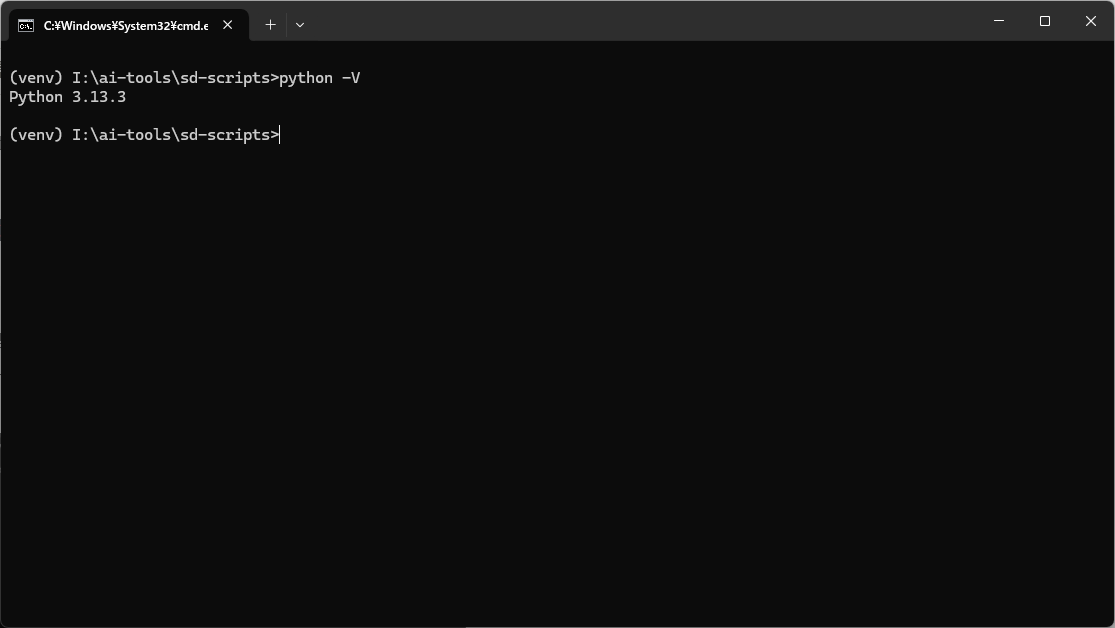
LoRA作成のコマンドを実行
先程実行環境に合わせ修正したコマンドをコマンドプロンプトにコピペ。(警告が出るが “強制的に貼り付け”)
※ちなみに、各行の最後に書かれている “^” は次の行に続くという意味
※また、PowerShellでは動かない(と思う)
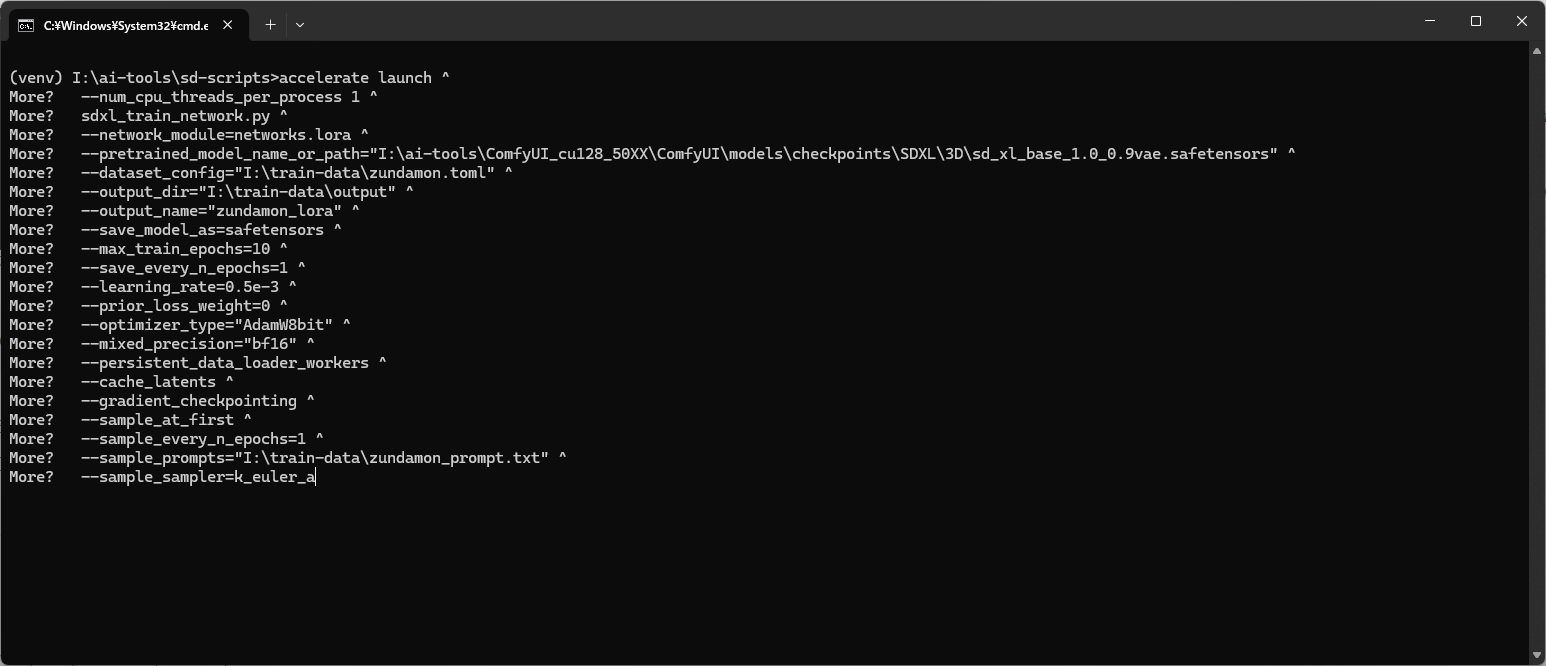
正しくペーストできたら Enter で実行。各パスの指定に誤りが無ければ動くと思われる。エラーが出たらそのへんを見直すと解決するかもしれない。
参考として私の環境で実行した時のログを載せておく。(警告が幾つかでているが “FutureWarning” など無視できるようなので問題ないと思われる)
(venv) I:\ai-tools\sd-scripts>accelerate launch ^
More? --num_cpu_threads_per_process 1 ^
More? sdxl_train_network.py ^
More? --network_module=networks.lora ^
More? --pretrained_model_name_or_path="I:\ai-tools\ComfyUI_cu128_50XX\ComfyUI\models\checkpoints\SDXL\3D\sd_xl_base_1.0_0.9vae.safetensors" ^
More? --dataset_config="I:\train-data\zundamon.toml" ^
More? --output_dir="I:\train-data\output" ^
More? --output_name="zundamon_lora" ^
More? --save_model_as=safetensors ^
More? --max_train_epochs=10 ^
More? --save_every_n_epochs=1 ^
More? --learning_rate=0.5e-3 ^
More? --prior_loss_weight=0 ^
More? --optimizer_type="AdamW8bit" ^
More? --mixed_precision="bf16" ^
More? --persistent_data_loader_workers ^
More? --cache_latents ^
More? --gradient_checkpointing ^
More? --sample_at_first ^
More? --sample_every_n_epochs=1 ^
More? --sample_prompts="I:\train-data\zundamon_prompt.txt" ^
More? --sample_sampler=k_euler_a
W0415 18:04:17.587000 10692 Lib\site-packages\torch\distributed\elastic\multiprocessing\redirects.py:29] NOTE: Redirects are currently not supported in Windows or MacOs.
W0415 18:04:19.751000 13376 venv\Lib\site-packages\torch\distributed\elastic\multiprocessing\redirects.py:29] NOTE: Redirects are currently not supported in Windows or MacOs.
I:\ai-tools\sd-scripts\venv\Lib\site-packages\diffusers\utils\outputs.py:63: FutureWarning: `torch.utils._pytree._register_pytree_node` is deprecated. Please use `torch.utils._pytree.register_pytree_node` instead.
torch.utils._pytree._register_pytree_node(
2025-04-15 18:04:20 INFO prepare tokenizers sdxl_train_util.py:138
I:\ai-tools\sd-scripts\venv\Lib\site-packages\transformers\tokenization_utils_base.py:1601: FutureWarning: `clean_up_tokenization_spaces` was not set. It will be set to `True` by default. This behavior will be depracted in transformers v4.45, and will be then set to `False` by default. For more details check this issue: https://github.com/huggingface/transformers/issues/31884
warnings.warn(
2025-04-15 18:04:21 INFO Loading dataset config from I:\train-data\zundamon.toml train_network.py:161
INFO prepare images. train_util.py:1686
INFO found directory I:\train-data\zundamon contains 12 image files train_util.py:1633
INFO 120 train images with repeating. train_util.py:1727
INFO 0 reg images. train_util.py:1730
WARNING no regularization images / 正則化画像が見つかりませんでした train_util.py:1735
INFO [Dataset 0] config_util.py:572
batch_size: 1
resolution: (1024, 1024)
enable_bucket: False
network_multiplier: 1.0
[Subset 0 of Dataset 0]
image_dir: "I:\train-data\zundamon"
image_count: 12
num_repeats: 10
shuffle_caption: True
keep_tokens: 2
keep_tokens_separator:
caption_separator: ,
secondary_separator: None
enable_wildcard: False
caption_dropout_rate: 0.0
caption_dropout_every_n_epoches: 0
caption_tag_dropout_rate: 0.0
caption_prefix: None
caption_suffix: None
color_aug: False
flip_aug: False
face_crop_aug_range: None
random_crop: False
token_warmup_min: 1,
token_warmup_step: 0,
alpha_mask: False,
is_reg: False
class_tokens: None
caption_extension: .txt
INFO [Dataset 0] config_util.py:578
INFO loading image sizes. train_util.py:901
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 12/12 [00:00<?, ?it/s]
INFO prepare dataset train_util.py:909
INFO preparing accelerator train_network.py:225
accelerator device: cuda
INFO loading model for process 0/1 sdxl_train_util.py:33
INFO load StableDiffusion checkpoint: sdxl_train_util.py:74
I:\ai-tools\ComfyUI_cu128_50XX\ComfyUI\models\checkpoints\SDXL\3D\sd_xl_base_1.0_0.9vae.safetensors
INFO building U-Net sdxl_model_util.py:198
INFO loading U-Net from checkpoint sdxl_model_util.py:202
2025-04-15 18:04:25 INFO U-Net: <All keys matched successfully> sdxl_model_util.py:208
INFO building text encoders sdxl_model_util.py:211
INFO loading text encoders from checkpoint sdxl_model_util.py:264
INFO text encoder 1: <All keys matched successfully> sdxl_model_util.py:278
2025-04-15 18:04:26 INFO text encoder 2: <All keys matched successfully> sdxl_model_util.py:282
INFO building VAE sdxl_model_util.py:285
INFO loading VAE from checkpoint sdxl_model_util.py:290
2025-04-15 18:04:27 INFO VAE: <All keys matched successfully> sdxl_model_util.py:293
import network module: networks.lora
INFO [Dataset 0] train_util.py:2195
INFO caching latents. train_util.py:1022
INFO checking cache validity... train_util.py:1049
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 12/12 [00:00<?, ?it/s]
INFO caching latents... train_util.py:1091
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 12/12 [00:04<00:00, 2.75it/s]
2025-04-15 18:04:32 INFO create LoRA network. base dim (rank): 4, alpha: 1 lora.py:935
INFO neuron dropout: p=None, rank dropout: p=None, module dropout: p=None lora.py:936
INFO create LoRA for Text Encoder 1: lora.py:1027
INFO create LoRA for Text Encoder 2: lora.py:1027
INFO create LoRA for Text Encoder: 264 modules. lora.py:1035
INFO create LoRA for U-Net: 722 modules. lora.py:1043
INFO enable LoRA for text encoder: 264 modules lora.py:1084
INFO enable LoRA for U-Net: 722 modules lora.py:1089
prepare optimizer, data loader etc.
INFO use 8-bit AdamW optimizer | {} train_util.py:4166
override steps. steps for 10 epochs is / 指定エポックまでのステップ数: 1200
running training / 学習開始
num train images * repeats / 学習画像の数×繰り返し回数: 120
num reg images / 正則化画像の数: 0
num batches per epoch / 1epochのバッチ数: 120
num epochs / epoch数: 10
batch size per device / バッチサイズ: 1
gradient accumulation steps / 勾配を合計するステップ数 = 1
total optimization steps / 学習ステップ数: 1200
steps: 0%| | 0/1200 [00:00<?, ?it/s]2025-04-15 18:04:41 INFO train_util.py:5455
INFO generating sample images at step / サンプル画像生成 ステップ: 0 train_util.py:5456
2025-04-15 18:04:42 INFO prompt: zundamon, 1girl, upper body, looking at viewer, simple background, masterpiece, best quality train_util.py:5611
INFO negative_prompt: low quality, worst quality, bad anatomy,bad composition, poor, low effort train_util.py:5612
INFO height: 1024 train_util.py:5613
INFO width: 1024 train_util.py:5614
INFO sample_steps: 25 train_util.py:5615
INFO scale: 7.5 train_util.py:5616
INFO sample_sampler: k_euler_a train_util.py:5617
INFO seed: 1 train_util.py:5619
I:\ai-tools\sd-scripts\venv\Lib\site-packages\torch\utils\checkpoint.py:86: UserWarning: None of the inputs have requires_grad=True. Gradients will be None
warnings.warn(
epoch 1/10
W0415 18:05:04.485000 10520 venv\Lib\site-packages\torch\distributed\elastic\multiprocessing\redirects.py:29] NOTE: Redirects are currently not supported in Windows or MacOs.
I:\ai-tools\sd-scripts\venv\Lib\site-packages\diffusers\utils\outputs.py:63: FutureWarning: `torch.utils._pytree._register_pytree_node` is deprecated. Please use `torch.utils._pytree.register_pytree_node` instead.
torch.utils._pytree._register_pytree_node(
W0415 18:05:07.070000 21328 venv\Lib\site-packages\torch\distributed\elastic\multiprocessing\redirects.py:29] NOTE: Redirects are currently not supported in Windows or MacOs.
I:\ai-tools\sd-scripts\venv\Lib\site-packages\diffusers\utils\outputs.py:63: FutureWarning: `torch.utils._pytree._register_pytree_node` is deprecated. Please use `torch.utils._pytree.register_pytree_node` instead.
torch.utils._pytree._register_pytree_node(
W0415 18:05:09.619000 25536 venv\Lib\site-packages\torch\distributed\elastic\multiprocessing\redirects.py:29] NOTE: Redirects are currently not supported in Windows or MacOs.
I:\ai-tools\sd-scripts\venv\Lib\site-packages\diffusers\utils\outputs.py:63: FutureWarning: `torch.utils._pytree._register_pytree_node` is deprecated. Please use `torch.utils._pytree.register_pytree_node` instead.
torch.utils._pytree._register_pytree_node(
W0415 18:05:12.182000 33536 venv\Lib\site-packages\torch\distributed\elastic\multiprocessing\redirects.py:29] NOTE: Redirects are currently not supported in Windows or MacOs.
I:\ai-tools\sd-scripts\venv\Lib\site-packages\diffusers\utils\outputs.py:63: FutureWarning: `torch.utils._pytree._register_pytree_node` is deprecated. Please use `torch.utils._pytree.register_pytree_node` instead.
torch.utils._pytree._register_pytree_node(
W0415 18:05:14.792000 13580 venv\Lib\site-packages\torch\distributed\elastic\multiprocessing\redirects.py:29] NOTE: Redirects are currently not supported in Windows or MacOs.
I:\ai-tools\sd-scripts\venv\Lib\site-packages\diffusers\utils\outputs.py:63: FutureWarning: `torch.utils._pytree._register_pytree_node` is deprecated. Please use `torch.utils._pytree.register_pytree_node` instead.
torch.utils._pytree._register_pytree_node(
W0415 18:05:17.404000 13492 venv\Lib\site-packages\torch\distributed\elastic\multiprocessing\redirects.py:29] NOTE: Redirects are currently not supported in Windows or MacOs.
I:\ai-tools\sd-scripts\venv\Lib\site-packages\diffusers\utils\outputs.py:63: FutureWarning: `torch.utils._pytree._register_pytree_node` is deprecated. Please use `torch.utils._pytree.register_pytree_node` instead.
torch.utils._pytree._register_pytree_node(
W0415 18:05:19.974000 18220 venv\Lib\site-packages\torch\distributed\elastic\multiprocessing\redirects.py:29] NOTE: Redirects are currently not supported in Windows or MacOs.
I:\ai-tools\sd-scripts\venv\Lib\site-packages\diffusers\utils\outputs.py:63: FutureWarning: `torch.utils._pytree._register_pytree_node` is deprecated. Please use `torch.utils._pytree.register_pytree_node` instead.
torch.utils._pytree._register_pytree_node(
W0415 18:05:22.592000 25912 venv\Lib\site-packages\torch\distributed\elastic\multiprocessing\redirects.py:29] NOTE: Redirects are currently not supported in Windows or MacOs.
I:\ai-tools\sd-scripts\venv\Lib\site-packages\diffusers\utils\outputs.py:63: FutureWarning: `torch.utils._pytree._register_pytree_node` is deprecated. Please use `torch.utils._pytree.register_pytree_node` instead.
torch.utils._pytree._register_pytree_node(
2025-04-15 18:05:23 INFO epoch is incremented. current_epoch: 0, epoch: 1 train_util.py:693
2025-04-15 18:05:23 INFO epoch is incremented. current_epoch: 0, epoch: 1 train_util.py:693
2025-04-15 18:05:23 INFO epoch is incremented. current_epoch: 0, epoch: 1 train_util.py:693
2025-04-15 18:05:23 INFO epoch is incremented. current_epoch: 0, epoch: 1 train_util.py:693
2025-04-15 18:05:23 INFO epoch is incremented. current_epoch: 0, epoch: 1 train_util.py:693
2025-04-15 18:05:23 INFO epoch is incremented. current_epoch: 0, epoch: 1 train_util.py:693
2025-04-15 18:05:23 INFO epoch is incremented. current_epoch: 0, epoch: 1 train_util.py:693
2025-04-15 18:05:23 INFO epoch is incremented. current_epoch: 0, epoch: 1 train_util.py:693
steps: 10%|██████████▎ | 120/1200 [05:09<46:29, 2.58s/it, avr_loss=0.0456]
saving checkpoint: I:\train-data\output\zundamon_lora-000001.safetensors
2025-04-15 18:09:52 INFO train_util.py:5455
INFO generating sample images at step / サンプル画像生成 ステップ: 120 train_util.py:5456
INFO prompt: zundamon, 1girl, upper body, looking at viewer, simple background, masterpiece, best quality train_util.py:5611
INFO negative_prompt: low quality, worst quality, bad anatomy,bad composition, poor, low effort train_util.py:5612
INFO height: 1024 train_util.py:5613
INFO width: 1024 train_util.py:5614
INFO sample_steps: 25 train_util.py:5615
INFO scale: 7.5 train_util.py:5616
INFO sample_sampler: k_euler_a train_util.py:5617
INFO seed: 1 train_util.py:5619
epoch 2/10
2025-04-15 18:10:31 INFO epoch is incremented. current_epoch: 1, epoch: 2 train_util.py:693
2025-04-15 18:10:31 INFO epoch is incremented. current_epoch: 1, epoch: 2 train_util.py:693
2025-04-15 18:10:31 INFO epoch is incremented. current_epoch: 1, epoch: 2 train_util.py:693
2025-04-15 18:10:31 INFO epoch is incremented. current_epoch: 1, epoch: 2 train_util.py:693
2025-04-15 18:10:31 INFO epoch is incremented. current_epoch: 1, epoch: 2 train_util.py:693
2025-04-15 18:10:31 INFO epoch is incremented. current_epoch: 1, epoch: 2 train_util.py:693
2025-04-15 18:10:31 INFO epoch is incremented. current_epoch: 1, epoch: 2 train_util.py:693
2025-04-15 18:10:31 INFO epoch is incremented. current_epoch: 1, epoch: 2 train_util.py:693
steps: 20%|████████████████████▌ | 240/1200 [12:04<48:18, 3.02s/it, avr_loss=0.0412]
saving checkpoint: I:\train-data\output\zundamon_lora-000002.safetensors
2025-04-15 18:16:46 INFO train_util.py:5455
INFO generating sample images at step / サンプル画像生成 ステップ: 240 train_util.py:5456
INFO prompt: zundamon, 1girl, upper body, looking at viewer, simple background, masterpiece, best quality train_util.py:5611
INFO negative_prompt: low quality, worst quality, bad anatomy,bad composition, poor, low effort train_util.py:5612
INFO height: 1024 train_util.py:5613
INFO width: 1024 train_util.py:5614
INFO sample_steps: 25 train_util.py:5615
INFO scale: 7.5 train_util.py:5616
INFO sample_sampler: k_euler_a train_util.py:5617
INFO seed: 1 train_util.py:5619
epoch 3/10
2025-04-15 18:21:08 INFO epoch is incremented. current_epoch: 2, epoch: 3 train_util.py:693
2025-04-15 18:21:08 INFO epoch is incremented. current_epoch: 2, epoch: 3 train_util.py:693
2025-04-15 18:21:08 INFO epoch is incremented. current_epoch: 2, epoch: 3 train_util.py:693
2025-04-15 18:21:08 INFO epoch is incremented. current_epoch: 2, epoch: 3 train_util.py:693
2025-04-15 18:21:08 INFO epoch is incremented. current_epoch: 2, epoch: 3 train_util.py:693
2025-04-15 18:21:08 INFO epoch is incremented. current_epoch: 2, epoch: 3 train_util.py:693
2025-04-15 18:21:08 INFO epoch is incremented. current_epoch: 2, epoch: 3 train_util.py:693
2025-04-15 18:21:08 INFO epoch is incremented. current_epoch: 2, epoch: 3 train_util.py:693
steps: 30%|██████████████████████████████▎ | 360/1200 [34:33<1:20:37, 5.76s/it, avr_loss=0.0464]
saving checkpoint: I:\train-data\output\zundamon_lora-000003.safetensors
2025-04-15 18:39:15 INFO train_util.py:5455
INFO generating sample images at step / サンプル画像生成 ステップ: 360 train_util.py:5456
INFO prompt: zundamon, 1girl, upper body, looking at viewer, simple background, masterpiece, best quality train_util.py:5611
INFO negative_prompt: low quality, worst quality, bad anatomy,bad composition, poor, low effort train_util.py:5612
INFO height: 1024 train_util.py:5613
INFO width: 1024 train_util.py:5614
INFO sample_steps: 25 train_util.py:5615
INFO scale: 7.5 train_util.py:5616
INFO sample_sampler: k_euler_a train_util.py:5617
INFO seed: 1 train_util.py:5619
epoch 4/10
2025-04-15 18:43:49 INFO epoch is incremented. current_epoch: 3, epoch: 4 train_util.py:693
2025-04-15 18:43:49 INFO epoch is incremented. current_epoch: 3, epoch: 4 train_util.py:693
2025-04-15 18:43:49 INFO epoch is incremented. current_epoch: 3, epoch: 4 train_util.py:693
2025-04-15 18:43:49 INFO epoch is incremented. current_epoch: 3, epoch: 4 train_util.py:693
2025-04-15 18:43:49 INFO epoch is incremented. current_epoch: 3, epoch: 4 train_util.py:693
2025-04-15 18:43:49 INFO epoch is incremented. current_epoch: 3, epoch: 4 train_util.py:693
2025-04-15 18:43:49 INFO epoch is incremented. current_epoch: 3, epoch: 4 train_util.py:693
2025-04-15 18:43:49 INFO epoch is incremented. current_epoch: 3, epoch: 4 train_util.py:693
steps: 40%|███████████████████████████████████████▌ | 480/1200 [1:07:31<1:41:17, 8.44s/it, avr_loss=0.0359]
saving checkpoint: I:\train-data\output\zundamon_lora-000004.safetensors
2025-04-15 19:12:14 INFO train_util.py:5455
INFO generating sample images at step / サンプル画像生成 ステップ: 480 train_util.py:5456
INFO prompt: zundamon, 1girl, upper body, looking at viewer, simple background, masterpiece, best quality train_util.py:5611
INFO negative_prompt: low quality, worst quality, bad anatomy,bad composition, poor, low effort train_util.py:5612
INFO height: 1024 train_util.py:5613
INFO width: 1024 train_util.py:5614
INFO sample_steps: 25 train_util.py:5615
INFO scale: 7.5 train_util.py:5616
INFO sample_sampler: k_euler_a train_util.py:5617
INFO seed: 1 train_util.py:5619
epoch 5/10
2025-04-15 19:17:18 INFO epoch is incremented. current_epoch: 4, epoch: 5 train_util.py:693
2025-04-15 19:17:18 INFO epoch is incremented. current_epoch: 4, epoch: 5 train_util.py:693
2025-04-15 19:17:18 INFO epoch is incremented. current_epoch: 4, epoch: 5 train_util.py:693
2025-04-15 19:17:18 INFO epoch is incremented. current_epoch: 4, epoch: 5 train_util.py:693
2025-04-15 19:17:18 INFO epoch is incremented. current_epoch: 4, epoch: 5 train_util.py:693
2025-04-15 19:17:18 INFO epoch is incremented. current_epoch: 4, epoch: 5 train_util.py:693
2025-04-15 19:17:18 INFO epoch is incremented. current_epoch: 4, epoch: 5 train_util.py:693
2025-04-15 19:17:18 INFO epoch is incremented. current_epoch: 4, epoch: 5 train_util.py:693
steps: 50%|█████████████████████████████████████████████████▌ | 600/1200 [1:22:06<1:22:06, 8.21s/it, avr_loss=0.0366]
saving checkpoint: I:\train-data\output\zundamon_lora-000005.safetensors
2025-04-15 19:26:48 INFO train_util.py:5455
INFO generating sample images at step / サンプル画像生成 ステップ: 600 train_util.py:5456
INFO prompt: zundamon, 1girl, upper body, looking at viewer, simple background, masterpiece, best quality train_util.py:5611
INFO negative_prompt: low quality, worst quality, bad anatomy,bad composition, poor, low effort train_util.py:5612
INFO height: 1024 train_util.py:5613
INFO width: 1024 train_util.py:5614
INFO sample_steps: 25 train_util.py:5615
INFO scale: 7.5 train_util.py:5616
INFO sample_sampler: k_euler_a train_util.py:5617
INFO seed: 1 train_util.py:5619
epoch 6/10
2025-04-15 19:29:39 INFO epoch is incremented. current_epoch: 5, epoch: 6 train_util.py:693
2025-04-15 19:29:39 INFO epoch is incremented. current_epoch: 5, epoch: 6 train_util.py:693
2025-04-15 19:29:39 INFO epoch is incremented. current_epoch: 5, epoch: 6 train_util.py:693
2025-04-15 19:29:39 INFO epoch is incremented. current_epoch: 5, epoch: 6 train_util.py:693
2025-04-15 19:29:39 INFO epoch is incremented. current_epoch: 5, epoch: 6 train_util.py:693
2025-04-15 19:29:39 INFO epoch is incremented. current_epoch: 5, epoch: 6 train_util.py:693
2025-04-15 19:29:39 INFO epoch is incremented. current_epoch: 5, epoch: 6 train_util.py:693
2025-04-15 19:29:39 INFO epoch is incremented. current_epoch: 5, epoch: 6 train_util.py:693
steps: 60%|███████████████████████████████████████████████████████████▍ | 720/1200 [1:34:20<1:02:53, 7.86s/it, avr_loss=0.0366]
saving checkpoint: I:\train-data\output\zundamon_lora-000006.safetensors
2025-04-15 19:39:02 INFO train_util.py:5455
INFO generating sample images at step / サンプル画像生成 ステップ: 720 train_util.py:5456
INFO prompt: zundamon, 1girl, upper body, looking at viewer, simple background, masterpiece, best quality train_util.py:5611
INFO negative_prompt: low quality, worst quality, bad anatomy,bad composition, poor, low effort train_util.py:5612
INFO height: 1024 train_util.py:5613
INFO width: 1024 train_util.py:5614
INFO sample_steps: 25 train_util.py:5615
INFO scale: 7.5 train_util.py:5616
INFO sample_sampler: k_euler_a train_util.py:5617
INFO seed: 1 train_util.py:5619
epoch 7/10
2025-04-15 19:41:49 INFO epoch is incremented. current_epoch: 6, epoch: 7 train_util.py:693
2025-04-15 19:41:49 INFO epoch is incremented. current_epoch: 6, epoch: 7 train_util.py:693
2025-04-15 19:41:49 INFO epoch is incremented. current_epoch: 6, epoch: 7 train_util.py:693
2025-04-15 19:41:49 INFO epoch is incremented. current_epoch: 6, epoch: 7 train_util.py:693
2025-04-15 19:41:49 INFO epoch is incremented. current_epoch: 6, epoch: 7 train_util.py:693
2025-04-15 19:41:49 INFO epoch is incremented. current_epoch: 6, epoch: 7 train_util.py:693
2025-04-15 19:41:49 INFO epoch is incremented. current_epoch: 6, epoch: 7 train_util.py:693
2025-04-15 19:41:49 INFO epoch is incremented. current_epoch: 6, epoch: 7 train_util.py:693
steps: 70%|██████████████████████████████████████████████████████████████████████▋ | 840/1200 [1:46:53<45:48, 7.64s/it, avr_loss=0.0334]
saving checkpoint: I:\train-data\output\zundamon_lora-000007.safetensors
2025-04-15 19:51:35 INFO train_util.py:5455
INFO generating sample images at step / サンプル画像生成 ステップ: 840 train_util.py:5456
INFO prompt: zundamon, 1girl, upper body, looking at viewer, simple background, masterpiece, best quality train_util.py:5611
INFO negative_prompt: low quality, worst quality, bad anatomy,bad composition, poor, low effort train_util.py:5612
INFO height: 1024 train_util.py:5613
INFO width: 1024 train_util.py:5614
INFO sample_steps: 25 train_util.py:5615
INFO scale: 7.5 train_util.py:5616
INFO sample_sampler: k_euler_a train_util.py:5617
INFO seed: 1 train_util.py:5619
epoch 8/10
2025-04-15 19:54:23 INFO epoch is incremented. current_epoch: 7, epoch: 8 train_util.py:693
2025-04-15 19:54:23 INFO epoch is incremented. current_epoch: 7, epoch: 8 train_util.py:693
2025-04-15 19:54:23 INFO epoch is incremented. current_epoch: 7, epoch: 8 train_util.py:693
2025-04-15 19:54:23 INFO epoch is incremented. current_epoch: 7, epoch: 8 train_util.py:693
2025-04-15 19:54:23 INFO epoch is incremented. current_epoch: 7, epoch: 8 train_util.py:693
2025-04-15 19:54:23 INFO epoch is incremented. current_epoch: 7, epoch: 8 train_util.py:693
2025-04-15 19:54:23 INFO epoch is incremented. current_epoch: 7, epoch: 8 train_util.py:693
2025-04-15 19:54:23 INFO epoch is incremented. current_epoch: 7, epoch: 8 train_util.py:693
steps: 80%|█████████████████████████████████████████████████████████████████████████████████▌ | 960/1200 [1:59:28<29:52, 7.47s/it, avr_loss=0.035]
saving checkpoint: I:\train-data\output\zundamon_lora-000008.safetensors
2025-04-15 20:04:10 INFO train_util.py:5455
INFO generating sample images at step / サンプル画像生成 ステップ: 960 train_util.py:5456
INFO prompt: zundamon, 1girl, upper body, looking at viewer, simple background, masterpiece, best quality train_util.py:5611
INFO negative_prompt: low quality, worst quality, bad anatomy,bad composition, poor, low effort train_util.py:5612
INFO height: 1024 train_util.py:5613
INFO width: 1024 train_util.py:5614
INFO sample_steps: 25 train_util.py:5615
INFO scale: 7.5 train_util.py:5616
INFO sample_sampler: k_euler_a train_util.py:5617
INFO seed: 1 train_util.py:5619
epoch 9/10
2025-04-15 20:06:57 INFO epoch is incremented. current_epoch: 8, epoch: 9 train_util.py:693
2025-04-15 20:06:57 INFO epoch is incremented. current_epoch: 8, epoch: 9 train_util.py:693
2025-04-15 20:06:57 INFO epoch is incremented. current_epoch: 8, epoch: 9 train_util.py:693
2025-04-15 20:06:57 INFO epoch is incremented. current_epoch: 8, epoch: 9 train_util.py:693
2025-04-15 20:06:57 INFO epoch is incremented. current_epoch: 8, epoch: 9 train_util.py:693
2025-04-15 20:06:57 INFO epoch is incremented. current_epoch: 8, epoch: 9 train_util.py:693
2025-04-15 20:06:57 INFO epoch is incremented. current_epoch: 8, epoch: 9 train_util.py:693
2025-04-15 20:06:57 INFO epoch is incremented. current_epoch: 8, epoch: 9 train_util.py:693
steps: 90%|██████████████████████████████████████████████████████████████████████████████████████████ | 1080/1200 [2:07:28<14:09, 7.08s/it, avr_loss=0.0304]
saving checkpoint: I:\train-data\output\zundamon_lora-000009.safetensors
2025-04-15 20:12:10 INFO train_util.py:5455
INFO generating sample images at step / サンプル画像生成 ステップ: 1080 train_util.py:5456
INFO prompt: zundamon, 1girl, upper body, looking at viewer, simple background, masterpiece, best quality train_util.py:5611
INFO negative_prompt: low quality, worst quality, bad anatomy,bad composition, poor, low effort train_util.py:5612
INFO height: 1024 train_util.py:5613
INFO width: 1024 train_util.py:5614
INFO sample_steps: 25 train_util.py:5615
INFO scale: 7.5 train_util.py:5616
INFO sample_sampler: k_euler_a train_util.py:5617
INFO seed: 1 train_util.py:5619
epoch 10/10
2025-04-15 20:12:53 INFO epoch is incremented. current_epoch: 9, epoch: 10 train_util.py:693
2025-04-15 20:12:53 INFO epoch is incremented. current_epoch: 9, epoch: 10 train_util.py:693
2025-04-15 20:12:53 INFO epoch is incremented. current_epoch: 9, epoch: 10 train_util.py:693
2025-04-15 20:12:53 INFO epoch is incremented. current_epoch: 9, epoch: 10 train_util.py:693
2025-04-15 20:12:53 INFO epoch is incremented. current_epoch: 9, epoch: 10 train_util.py:693
2025-04-15 20:12:53 INFO epoch is incremented. current_epoch: 9, epoch: 10 train_util.py:693
2025-04-15 20:12:53 INFO epoch is incremented. current_epoch: 9, epoch: 10 train_util.py:693
2025-04-15 20:12:53 INFO epoch is incremented. current_epoch: 9, epoch: 10 train_util.py:693
steps: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████| 1200/1200 [2:13:23<00:00, 6.67s/it, avr_loss=0.036]2025-04-15 20:18:04 INFO train_util.py:5455
INFO generating sample images at step / サンプル画像生成 ステップ: 1200 train_util.py:5456
INFO prompt: zundamon, 1girl, upper body, looking at viewer, simple background, masterpiece, best quality train_util.py:5611
INFO negative_prompt: low quality, worst quality, bad anatomy,bad composition, poor, low effort train_util.py:5612
INFO height: 1024 train_util.py:5613
INFO width: 1024 train_util.py:5614
INFO sample_steps: 25 train_util.py:5615
INFO scale: 7.5 train_util.py:5616
INFO sample_sampler: k_euler_a train_util.py:5617
INFO seed: 1 train_util.py:5619
saving checkpoint: I:\train-data\output\zundamon_lora.safetensors
2025-04-15 20:18:47 INFO model saved. train_network.py:1112
steps: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████| 1200/1200 [2:14:06<00:00, 6.71s/it, avr_loss=0.036]
(venv) I:\ai-tools\sd-scripts>出来上がった LoRA
“output” フォルダに作成された LoRA が保存される。
今回は10エポック実行し、毎エポック LoRA を出力する設定だったので強度が異なる10種類の LoRA が作成された。
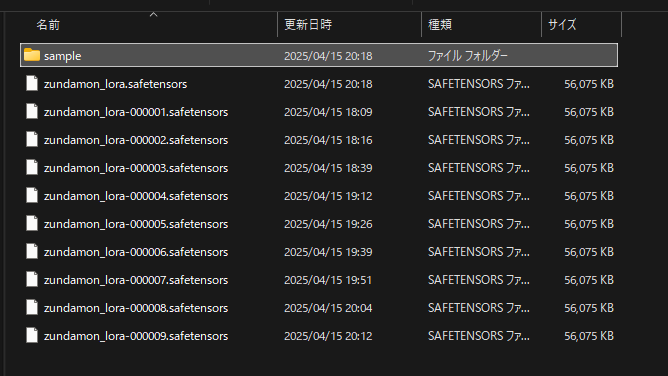
また、サンプルイメージの出力設定をしたので “output\sample” エポック毎に生成されたイメージが作成されていた。サンプルイメージをざっと見てみると 120 steps から特徴が出始め、720 steps 辺りから色味が安定し始めたように感じる。











作成したLoRAのテスト
サンプルイメージはサンプルイメージとして、実際に出来上がった LoRA でイメージ生成を試す。
ComfyUI上で作成した LoRA を読み込ませ、プロンプトにはトレーニングで使用したキャプションを使いイメージ生成をしてみた。
zundamon, shorts, 1girl, solo, suspenders, green shorts, full body, shirt, short sleeves, suspender shorts, white shirt, green footwear, white background, standing, hand on hip, simple background, clenched hand, puffy sleeves, looking at viewer, hand up, smile, puffy short sleeves, closed mouth, shoes, masterpiece,best quality
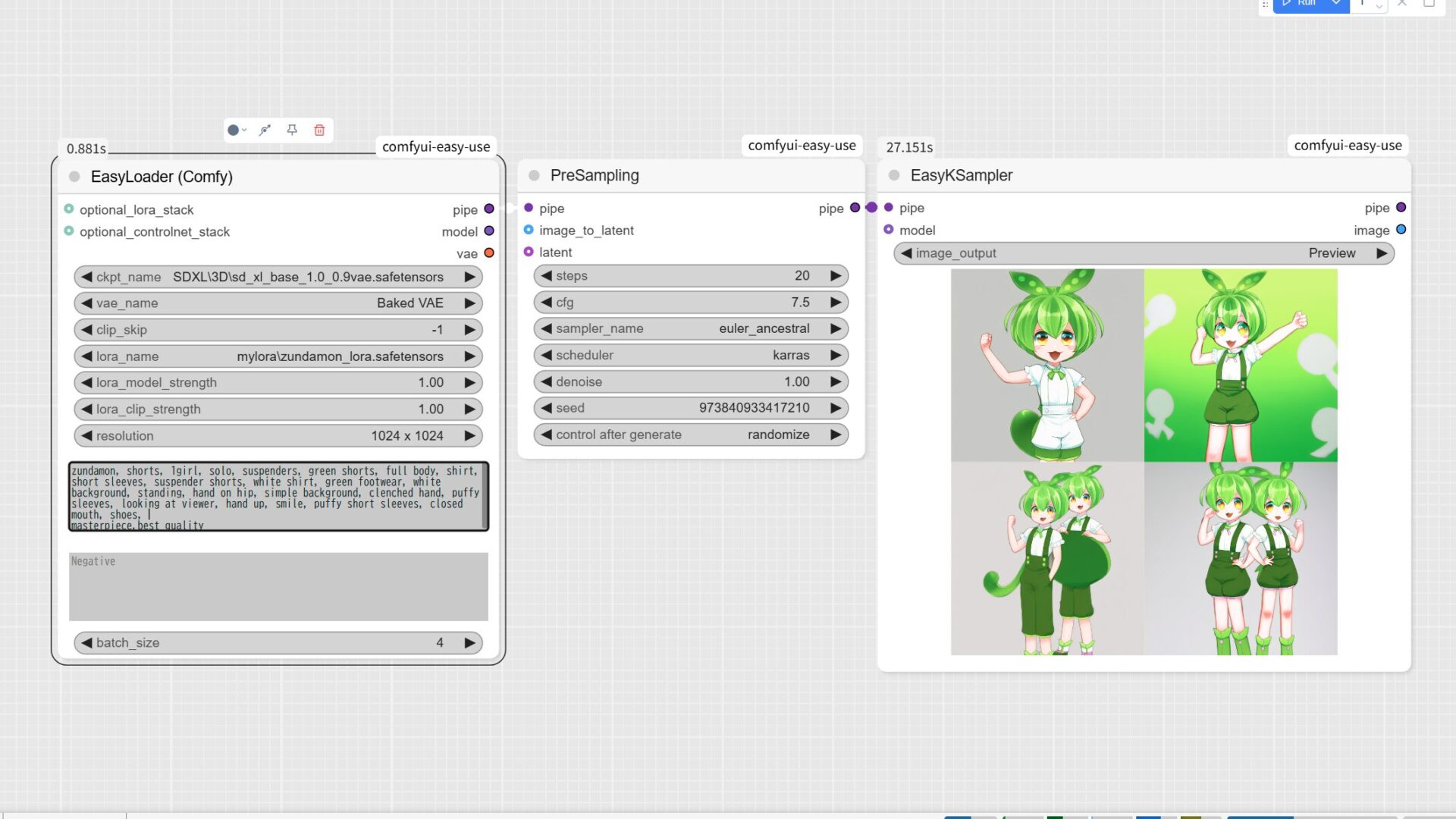
複数人になったりパーツのバランスが気になるが、概ねずんだもんと分かるイラストが生成された。




さいごに
ゴールにしていた LoRA の作成は達成できたので一先ず良しとしておく。ただ、まだまだ試せていない事も山程あるので暇な時間ができたら色々とやってみようと思う。
それと RTX50シリーズ に起因する問題・・・。なんとか回避自体はできたものの、これに時間を取られたのが勿体なかった。まぁ、今後はその辺も対応されていくだろうし、こまめにチェックですな。

コメント